

前言
Nexus 是开源的 Maven 私服仓库,同时 Nexus 还支持 Npm 、 .Net、Golang 、Python 等开发语言的包管理。Nexus 也是我们重度使用的一个应用,Nexus 保存着 Tap 各开发组的代码构建产物。Nexus 出现问题会导致项目 CI 、CD 流程阻断。本文旨在通过 Prometheus + Grafana 实现 Nexus 运行时监控观测,帮助运维人员更加了解 Nexus ,轻松从容应对线上各种疑难杂症。
- Nexus Version:3.29.2-02
metrics 采集
Nexus 提供了 Prometheus 格式数据的接口,这个接口需要授权 nx-metrics-all 才能访问,所以,将 metrics 采集到 Prometheus 里,需要做如下。
- metrics 接口:http://localhost:8081/service/metrics/prometheus
创建 metrics 接口权限账户
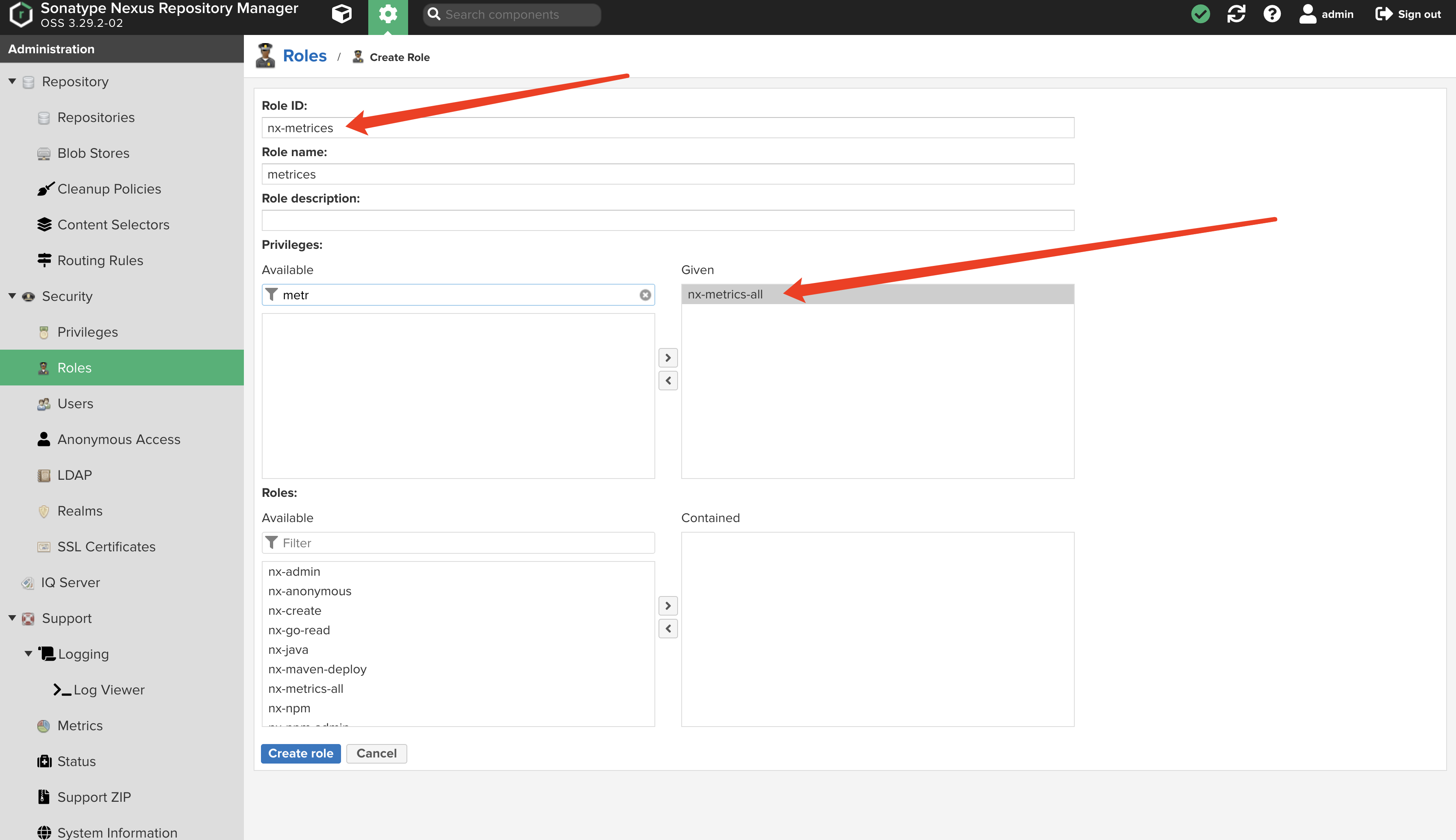
给指标接口创建一个单独的 metrics 账户,然后创建一个新的 Role(nx-metrics) , 将 nx-metrics-all 给这个角色,然后将角色给 metrics 账户。如下图。
配置 Prometheus
metrics 账户准备好后,在 Prometheus 侧添加如下配置项:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: []
scheme: http
timeout: 10s
scrape_configs:
- job_name: nxrm
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /service/metrics/prometheus
scheme: http
basic_auth:
username: metrics
password: metrics
static_configs:
- targets:
- localhost:8081
配置无误后,metrics 已经收集到 Prometheus 了。可以在 Prometheus 里查询 org_sonatype_nexus_ 打头的指标,有就代表配置成功了。
grafana 绘制面板
Nexus metrics 总共有超过 2k 多行。在绘制观测面板前,需要先分析下采集的 metrics 信息
分析 metrics
Nexus 暴露出来的指标,主要分三个类别:
- Component :相关组件的运行时指标,比如文件存储组件 FileBlobStore,以 org_sonatype_nexus_ 前缀开头的系列指标。
- Jetty :Web 容器,负责接收响应请求的,以 org_eclipse_jetty_ 前缀开头的系列指标。
- Jvm :Jvm Runtime,反应堆内存、非堆内存、GC 回收等,以 jvm_ 前缀开头的系列指标。
其中,Component 指标是最多的,也有部分 Component 根本就没有使用,指标一直为 0,这部分指标就可以不用绘制面板。
绘制观测面板
经过上面分析,可以绘制出如下观测面板。
Nexus Component
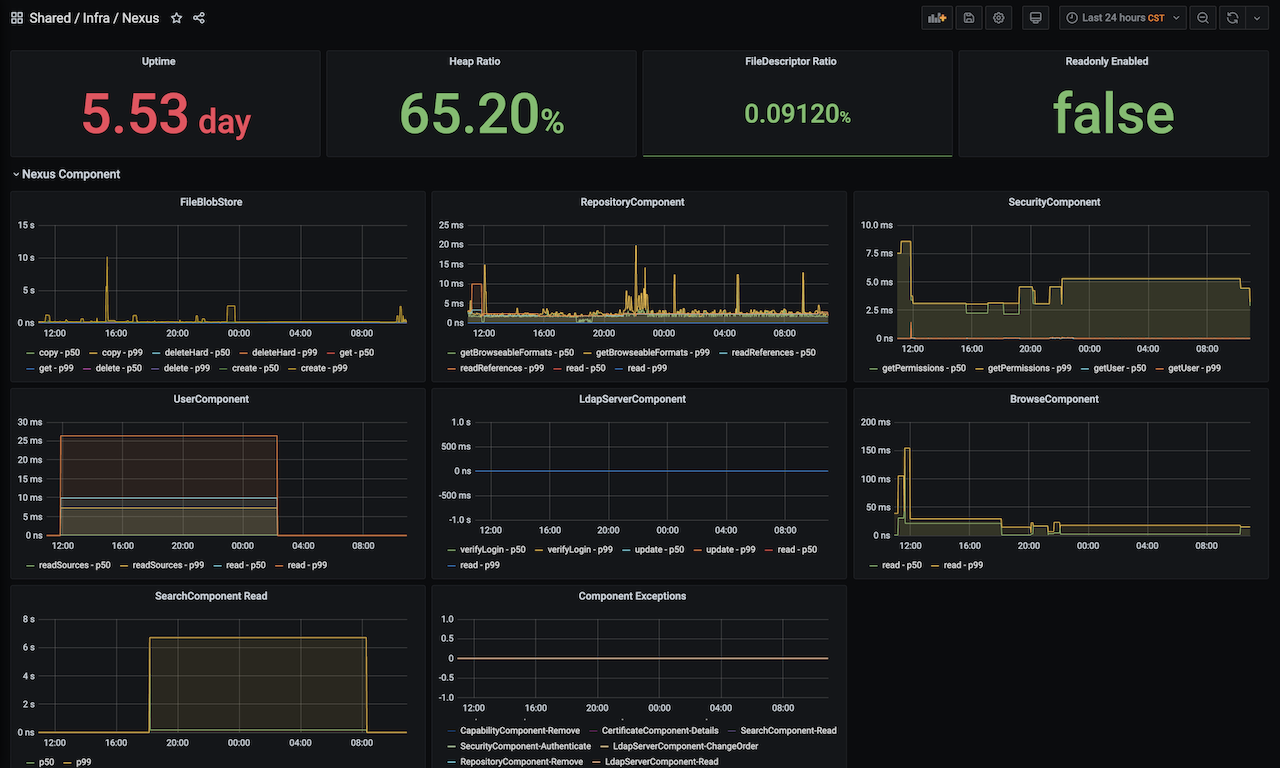
这个面板绘制了常用的组件运行信息,以 LdapServerComponent 为例,我们启用了这个组件,对接了公司内部的 LDAP 。之前有用户反馈登录失败,最后排查到是 Nexus 访问 LDAP Server 出现了问题,如果有了这个观测图,就能很清楚的看到 LdapServerComponent 内部的运行情况,快速定位问题。另外,Component Exceptions 面板也能集中观测到所有组件的异常信息,这里只要指标大于 0 ,就代表 Nexus 服务出问题了。
Jetty WebAppContext
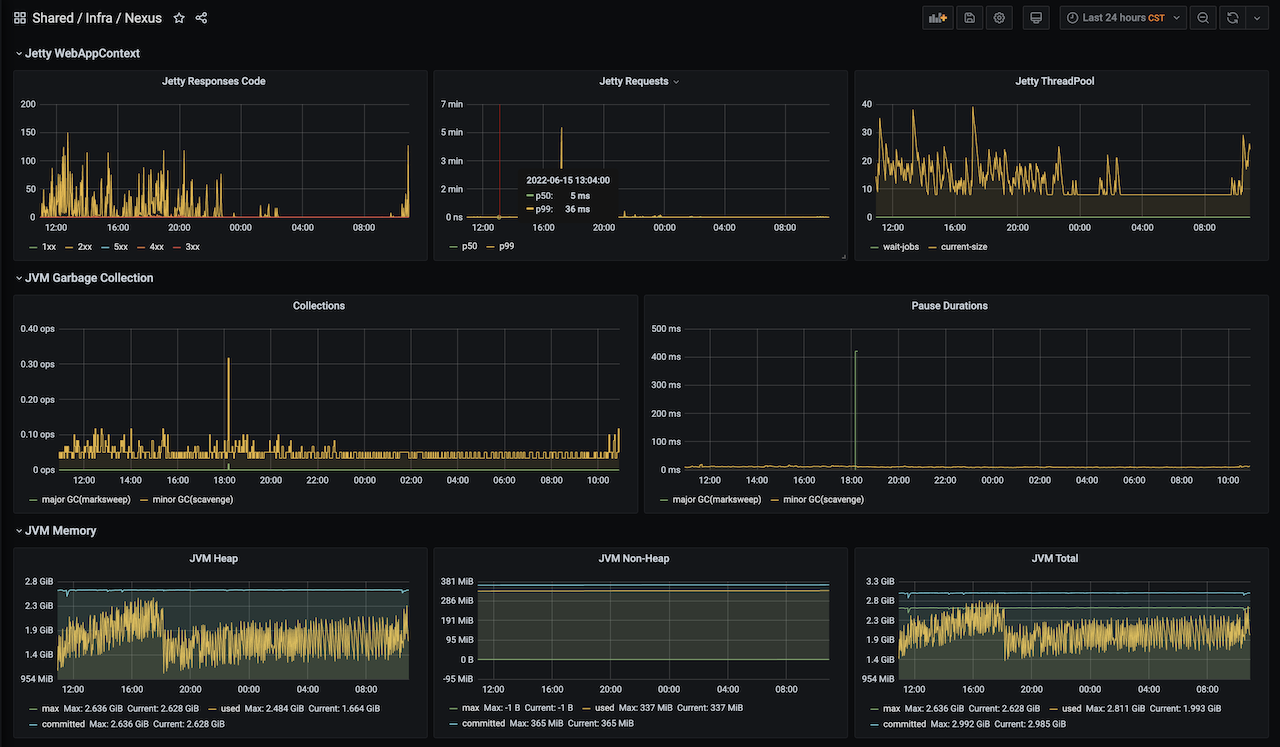
Jetty 面板反应了 Nexus 的流量情况,请求响应等信息。其中 Jetty 线程池,可以关注 wait-jobs(等待线程池执行的任务数) 这个指标,如果这个指标一直大于 0 ,则表示 Nexus Server 出现性能问题了。
Jvm Runtime
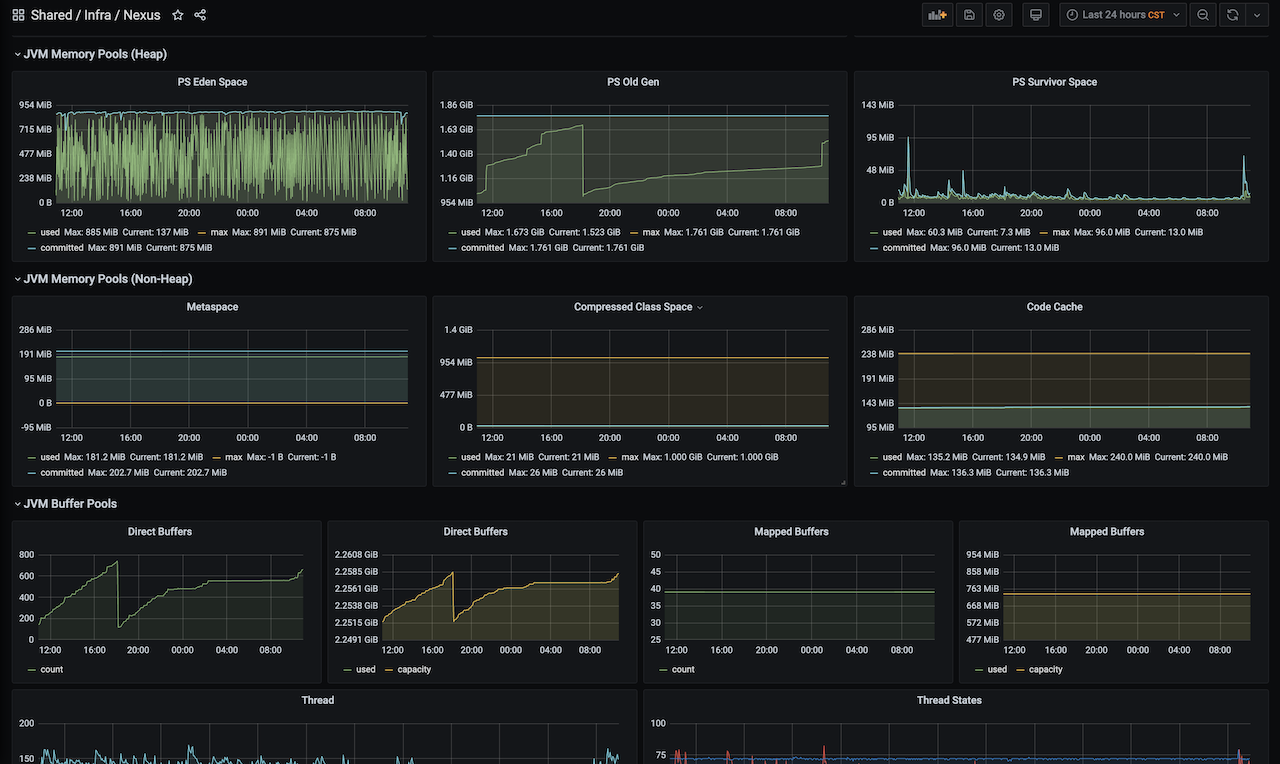
Jvm 的指标不用多说,和一般应用的 jvm 一样。它反应了应用的内存情况,包括堆内存和非堆内存,以及堆外内存,还有 GC 执行情况等。以内存观测为例,我们的 Nexus 服务是从 ECS 迁移的 K8s 环境中的,当时给 pod 的内存资源设置了 request 、limit 4G,给 jvm xmx 设置了 2G,运行后还会出现内存告警,实际使用内存远超 xmx 设置的大小。从贴出截图已经可以看出答案,是因为 Nexus 使用了超过 2G 的堆外内存(Direct Buffers + Mapped Buffers)。
结语
添加 Nexus 观测指标,一是可以清晰的了解这个软件的运行时情况,更加精准的给运行资源。二是方便出现类似问题时,可以快速排查问题。三是可以根据指标信息制定告警规则,比用户先一步发现问题。上面展示的 Grafana 面板已经分享到 Grafana Dashboards 市场了,可以通过如下链接找到 ID 直接导入到 Grafana 中,欢迎下载。
- Nexus Dashboards:https://grafana.com/grafana/dashboards/16459
