
前言碎语
昨天博主写了《windows环境下flink入门demo实例》实现了官方提供的最简单的单词计数功能,今天升级下,将数据源从socket流换成生产级的消息队列kafka来完成一样的单词计数功能。本文实现的重点主要有两个部分,一是kafka环境的搭建,二是如何使用官方提供的flink-connector-kafka_2.12来消费kafka消息,其他的逻辑部分和上文类似。
进入正题
本篇博文涉及到的软件工具以及下载地址:
Apache Flink :https://flink.apache.org/downloads.html ,请下载最新版1.7.x,选择单机版本
kafka:http://kafka.apache.org/downloads ,请下载最新的2.1.0
第一步:安装kafka,并验证
从上面的下载地址选择二进制包下载后是个压缩包,解压后的目录如下:
进入bin\windows下,找到kafka-server-start.bat和zookeeper-server-start.bat。配置文件在config目录下,主要配置一些日志和kafka server和zookeeper,都默认就好。如果你本地已经有zk的环境,就可以忽略zk,不然安装下面的步骤执行即可。
1. 启动zk服务
执行:zookeeper-server-start.bat ..\..\config\zookeeper.properties
2.启动kafka服务
执行:kafka-server-start.bat ..\..\config\server.properties
3.创建test主题
执行:kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
4.查看上一步的主题是否创建成功,成功的话控制台会输出test
执行:kafka-topics.bat --list --zookeeper localhost:2181
5.订阅test主题消息
执行:kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
6.发布消息
执行:kafka-console-producer.bat --broker-list localhost:9092 --topic test
以上步骤成功后,我们需要验证下是否都成功了。在第六条指令的窗口中输入abc。如果在第5个指令窗口输出了就代表kafka环境ok了。然后可以关掉第5个指令窗口,下面就让Flink来消费kafka的消息
第二步:编写消费kafka消息的Flink job
基础步骤参考《windows环境下flink入门demo实例》一文。唯一的区别就是因为要消费kafka中的数据,所以需要引入一个kafka连接器,官方已提供到maven仓库中,引入最新版本即可,如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.7.1</version>
</dependency>
然后新建一个KafkaToFlink类 ,代码逻辑和昨天的一样,都是从一段字符串中统计每个词语出现的次数,这个场景比较像我们的热搜关键字,我标题简化为热词统计了。主要的代码如下:
/**
* Created by kl on 2019/1/30.
* Content :消费kafka数据
*/
public class KafkaToFlink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* 这里主要配置KafkaConsumerConfig需要的属性,如:
* --bootstrap.servers localhost:9092 --topic test --group.id test-consumer-group
*/
ParameterTool parameterTool = ParameterTool.fromArgs(args);
DataStreamdataStream = env.addSource(new FlinkKafkaConsumer(parameterTool.getRequired("topic"), new SimpleStringSchema(), parameterTool.getProperties()));
DataStreamwindowCounts = dataStream.rebalance().flatMap(new FlatMapFunction() {
public void flatMap(String value, Collectorout) {
System.out.println("接收到kafka数据:" + value);
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
}).keyBy("word")
.timeWindow(Time.seconds(2))
.reduce(new ReduceFunction() {
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
windowCounts.print().setParallelism(1);
env.execute("KafkaToFlink");
}
}
注意下这个地方:ParameterTool.fromArgs(args);我们所有的关于KafkaConsumerConfig的配置,都是通过启动参数传入的,然后Flink提供了一个从args中获取参数的工具类。这里需要配置的就三个信息,和我们在命令窗口创建订阅一样的参数即可
第三步:验证Flink job是否符合预期
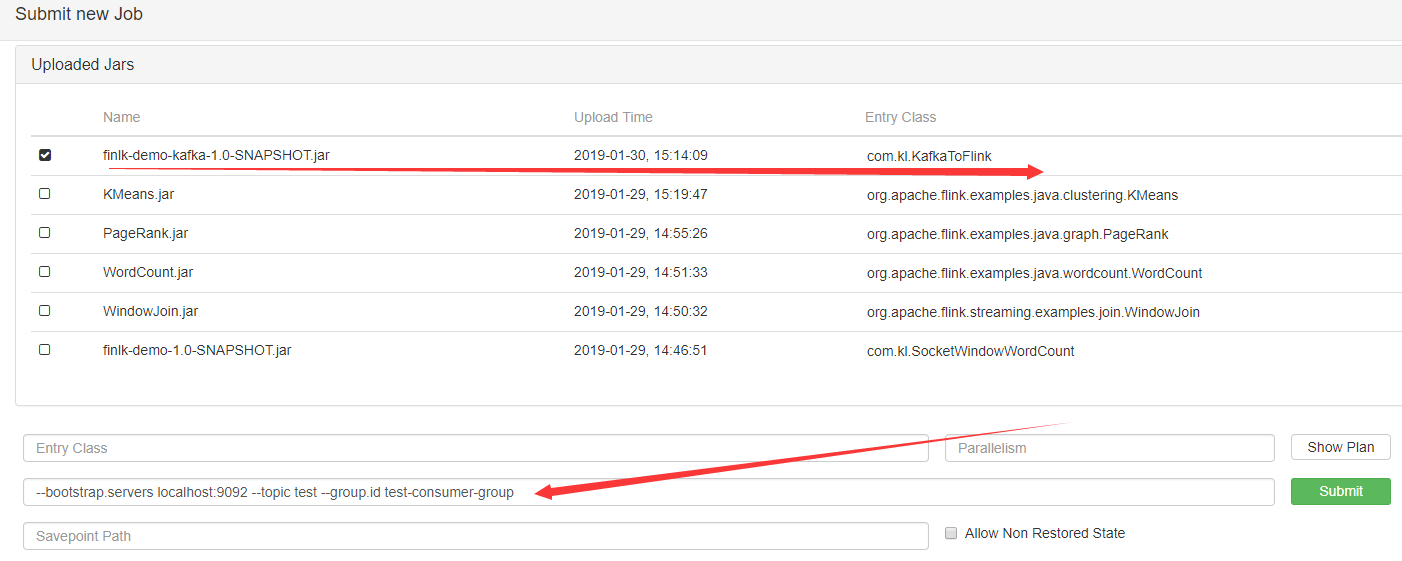
将应用打成jar包后通过Flink web上传到Flink Server。然后,找到你提交的job,输入如下的启动参数,提交submit即可:
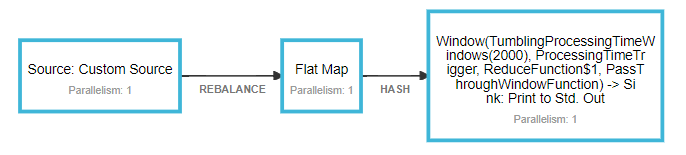
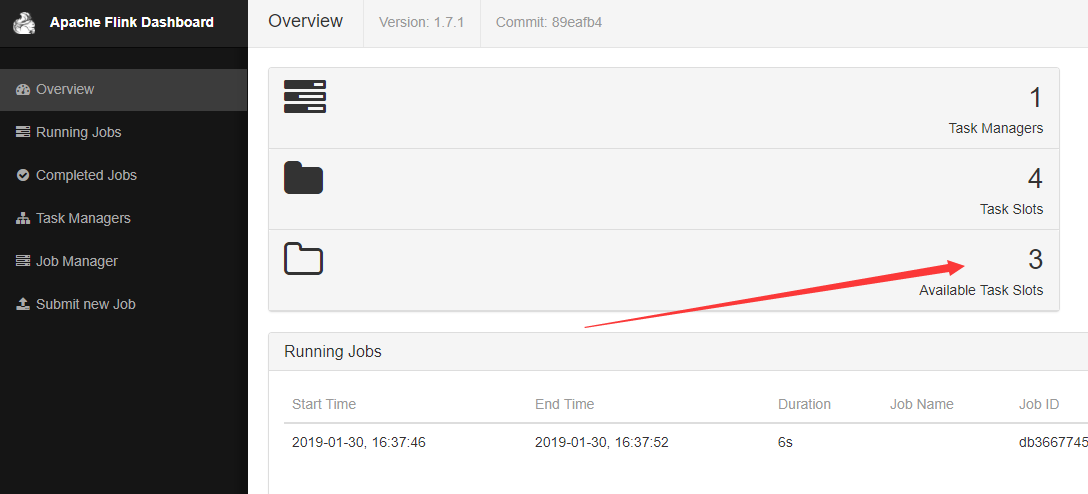
成功运行的job的页面如下图,如果下图框框中的指标一直在转圈圈,那么很有可能是因为你运行了其他的job,导致Available Task Slots不够用了。
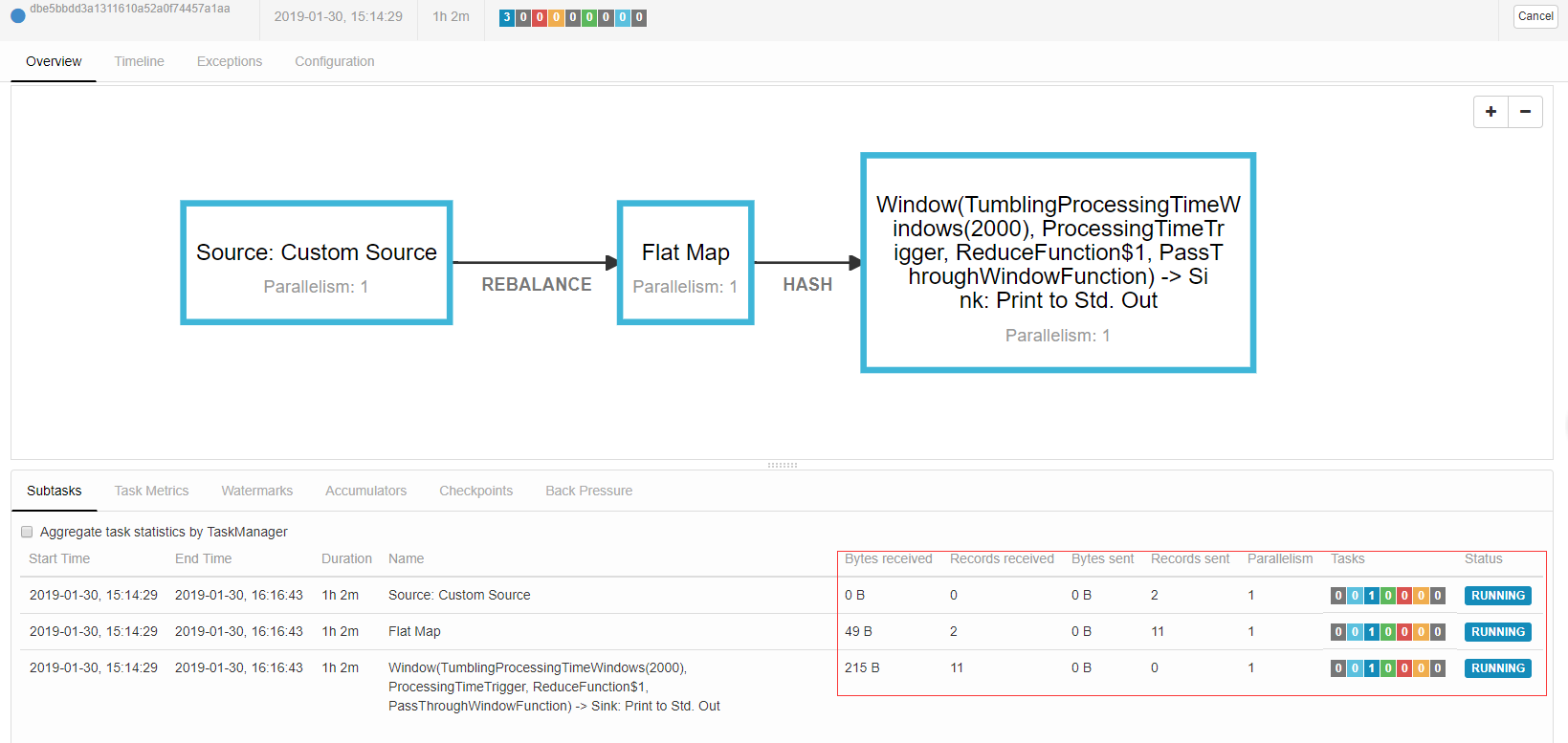
默认的Flink的Slots配置是1,当出现任务插槽不够用时,上图圈圈转一会就会失败,然后打开job manager 点击log就可以看到job因为没有可用的任务插槽而失败了。
org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not allocate all requires slots within timeout of 300000 ms. Slots required: 2, slots allocated: 0 at org.apache.flink.runtime.executiongraph.ExecutionGraph.lambda$scheduleEager$3(ExecutionGraph.java:991) at java.util.concurrent.CompletableFuture.uniExceptionally(CompletableFuture.java:870) at java.util.concurrent.CompletableFuture$UniExceptionally.tryFire(CompletableFuture.java:852) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.concurrent.FutureUtils$ResultConjunctFuture.handleCompletedFuture(FutureUtils.java:535) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:772) at akka.dispatch.OnComplete.internal(Future.scala:258) at akka.dispatch.OnComplete.internal(Future.scala:256) at akka.dispatch.japi$CallbackBridge.apply(Future.scala:186) at akka.dispatch.japi$CallbackBridge.apply(Future.scala:183) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36) at org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:83) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252) at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:534) at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:20) at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:18) at scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436) at scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36) at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55) at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91) at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91) at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91) at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:90) at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39) at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
上面的问题可以通过修改conf/flink-conf.yaml中的taskmanager.numberOfTaskSlots来设置,具体指单个TaskManager可以运行的并行操作员或用户功能实例的数量。如果此值大于1,则单个TaskManager将获取函数或运算符的多个实例。这样,TaskManager可以使用多个CPU内核,但同时,可用内存在不同的操作员或功能实例之间划分。此值通常与TaskManager的计算机具有的物理CPU核心数成比例(例如,等于核心数,或核心数的一半)。当然,如果你修改了配置文件,Flink Server是需要重启的。重启成功后,可以在大盘看到,如下图箭头:
一切就绪后,在kafka-console-producer窗口中输入字符串回车,就会在flink job窗口中看到相关的信息了,效果前文一样,如图:

文末结语
本文算昨天hello wrod入门程序的升级版,实现了消费kafka中的消息来统计热词的功能。后面生产环境也打算使用kafka来传递从mysql binlog中心解析到的消息,算是一个生产实例的敲门砖吧。正如博主昨天所说的,落地的过程肯定会有很多问题,像上面的taskmanager.numberOfTaskSlots的设置。后面会继续将我们落地过程中的问题记录下来,欢迎关注凯京科技一起交流。
作者简介:
陈凯玲,2016年5月加入凯京科技。曾任职高级研发和项目经理,现任凯京科技研发中心架构&运维部负责人。pmp项目管理认证拥有者,阿里云认证最有价值专家MVP。热爱开源,先后开源过多个热门项目。热爱分享技术点滴,独立博客KL博客(http://www.kailing.pub)博主。
欢迎加入凯京开源技术QQ群:613025121,和我们一起交流互联网应用的技术架构落地实践
关于架构&运维部
凯京研发中心架构&运维部的工作主要分两大部分,架构部分主要负责框架中间件的研究,如dubbo、apollo、skywalking、xxljob、分布式事务等、公司内开源项目(https://gitee.com/kekingcn)以及公共服务公共组件的研发维护、新技术的引进以及落地等。运维部分主要负责devops系统研发以及k8s容器环境的维护等工作。
架构组招聘
目前架构组还有两个虚位以待,欢迎志同道合的你来和我们一起交流。简历可发送至邮箱:chenkailing@keking.cn
