
前言一定要看到最后
早就听说Go语言开发的服务不用任何架构优化,就可以轻松实现百万级别的qps。这得益于Go语言级别的协程的处理效率。协程不同于线程,线程是操作系统级别的资源,创建线程,调度线程,销毁线程都是重量级别的操作。而且线程的资源有限,在java中大量的不加限制的创建线程非常容易将系统搞垮。接下来要分享的这个开源项目,正是解决了在java中只能使用多线程模型开发高并发应用的窘境,使得java也能像Go语言那样使用协程的语义开发了。
- quasar项目地址:https://github.com/puniverse/quasar
- quasar周边项目地址:https://github.com/puniverse/comsat
快速体验
添加依赖
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.7.10</version>
</dependency>
添加java agent
quasar的实现原理是在java加载class前,通过jdk的instrument机制使用asm来修改目标class的字节码来实现的,他标记了协程代码的起始和结束的位置,以及方法需要暂停的位置,每个协程任务统一由FiberScheduler去调度,内部维护了一个或多个ForkJoinPool实例。所以,在运行应用前,需要配置好quasar-core的java agent地址,在vm参数上加上如下脚本即可:
-javaagent:D:\.m2\repository\co\paralleluniverse\quasar-core\0.7.10\quasar-core-0.7.10.jar
线程VS协程
下面模拟调用某个远程的服务,假设远程服务处理耗时需要1S,这里使用执行阻塞1S来模拟,分别看多线程模型和协程模型调用这个服务10000次所需的耗时
协程代码
public static void main(String[] args) throws Exception{
CountDownLatch count = new CountDownLatch(10000);
StopWatch stopWatch = new StopWatch();stopWatch.start();
IntStream.range(0,10000).forEach(i-> new Fiber() {
@Override
protected String run() throws SuspendExecution, InterruptedException {
Strand.sleep(1000 );
count.countDown();
return "aa";
}
}.start());
count.await();stopWatch.stop();
System.out.println("结束了: " + stopWatch.prettyPrint());
}
耗时情况:
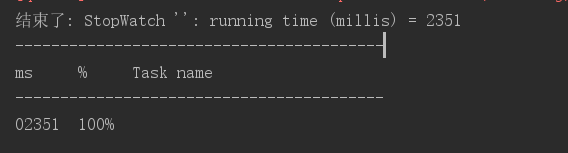
多线程代码
public static void main(String[] args) throws Exception{
CountDownLatch count = new CountDownLatch(10000);
StopWatch stopWatch = new StopWatch();stopWatch.start();
ExecutorService executorService = Executors.newCachedThreadPool();
IntStream.range(0,10000).forEach(i-> executorService.submit(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException ex) { }
count.countDown();
}));
count.await();stopWatch.stop();
System.out.println("结束了: " + stopWatch.prettyPrint());
}
耗时情况
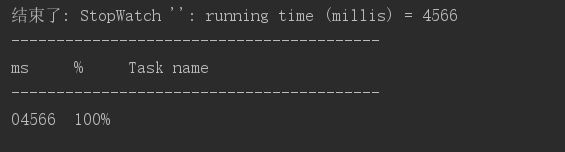
协程完胜
可以看到上面的结果,在对比访问一个耗时1s的服务10000次时,协程只需要2秒多,而多线程模型需要4秒多,时效相差了一倍。而且上面多线程编程时,并没有指定线程池的大小,在实际开发中是绝不允许的。一般我们会设置一个固定大小的线程池,因为线程资源是宝贵,线程多了费内存还会带来线程切换的开销。上面的场景在设置200个固定大小线程池时。结果也是可预见的达到了50多秒。这个结果足以证明协程编程ko线程编程了。而且在qps越大时,线程处理的效率和协程的差距就约明显,缩小差距的唯一方式就是增加线程数,而这带来的影响就是内存消耗激增。而反观协程,基于固定的几个线程调度,可以轻松实现百万级的协程处理,而且内存稳稳的。
后记
最后,博主以为Quasar只是一个框架层面的东西,所以就又去看了下同样是jvm语言的kotlin的协程。他的语言更简洁,可以直接和java混合使用。跑上面这种实例只需要1秒多。
fun main() {
val count = CountDownLatch(10000)
val stopWatch = StopWatch()
stopWatch.start()
IntStream.range(0,10000).forEach {
GlobalScope.launch {
delay(1000L)
println(Thread.currentThread().name + "->"+ it)
count.countDown()
}
}
count.await()
stopWatch.stop()
println("结束了: " + stopWatch.prettyPrint())
}
当博主看到这个结果的时候,有种震惊的赶脚,kotlin的同步模型牛逼呀,瞬时感觉到发现了java里的骚操作了,可以使用kotlin的协程来代替java中的多线程操作。因为他们两个混合开发毫无压力。如果行的通,那就太爽了。所以就有下面这个kotlin协程实现的代码:
@Service
class KotlinAsyncService(private val weatherService: GetWeatherService,private val demoApplication: DemoApplication){
val weatherUrl = "http://localhost:8080/demo/mockWeatherApi?city="
fun getHuNanWeather(): JSONObject{
val result = JSONObject()
val count = CountDownLatch(demoApplication.weatherContext.size)
for (city in demoApplication.weatherContext){
val url = weatherUrl + city.key
GlobalScope.launch {
result[city.key.toString()] = weatherService.get(url)
count.countDown()
}
}
count.await()
return result
}
}
现实是,当我使用协程替换掉我java多线程写的一个多线程汇聚多个http接口的结果的接口时,通过ab压测他们两个的性能并没有很大的变化,最后了解到主要原因是这个时候,在协程里发起一个http的请求时,涉及到操作系统层面的socket io操作,io操作是阻塞的,协程的并发也就变成了调度协程的几个线程的并发了。而且当我把同样的代码放到Quasar中的时候,Quasar直接抛io异常了,说明Quasar还并不能轻松支持这个场景。那为什么上面的测试结果差距这么大呢,是因为我错误的把协程实现里的阻塞等同于线程的阻塞。协程里的delay挂起函数,会立马释放线程到线程池,但是当真正的io阻塞的时候也就和真正的线程sleep一样了,并没有释放当前的线程。所以这些对比都没有太大的意义。
