
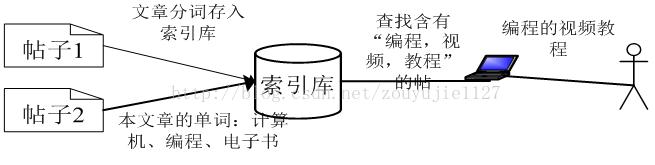
前言
从入门的demo,到了解原理到了解结构,继而学习工具,现在我们可以用Lucene来做简单的数据增删改查操作了
直接上代码
ps:代码注释比较全,鉴于作者的水平,有些东西可能未理解到位。推荐使用Luke来配合测试,了解Luke可参考我的上一篇博文:http://www.kailing.pub/article/index/arcid/74.html
package com.kl.Lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.nio.file.Paths;
/**
* @author kl by 2016/3/14
* @boke www.kailing.pub
*/
public class IndexerCURD {
//测试数据,模拟数据库表结构
private static String[] ids={"1","2","3"}; //用户ID
private static String [] names={"kl","wn","sb"};
private static String [] describes={"shi yi ge mei nan zi","Don't know","Is an idiot\n"};
//索引存储地址
private static String indexDir="E:\\javaEEworkspace\\LuceneDemo\\LuceneIndex";
/**
* 获取操作索引实体,并添加测试数据
* @param indexDir 索引存储位置
* @return
* @throws Exception
*/
public static IndexWriter getIndexWriter(String indexDir)throws Exception{
IndexWriterConfig writerConfig=new IndexWriterConfig(getAnalyzer());
IndexWriter indexWriter=new IndexWriter(getDirectory(indexDir),writerConfig);
Document document=new Document();
//Field.Store.YES或者NO(存储域选项)
//设置为YES表示或把这个域中的内容完全存储到文件中,方便进行文本的还原
//设置为NO表示把这个域的内容不存储到文件中,但是可以被索引,此时内容无法完全还原(doc.get)
for(int i=0;i<ids.length;i++){
document.add(new StringField("ids",ids[i], Field.Store.YES));
document.add(new StringField("names",names[i], Field.Store.YES));
document.add(new TextField("describes",describes[i], Field.Store.YES));
indexWriter.addDocument(document);
}
return indexWriter;
}
/**
* 得到默认分词器
* @return
*/
public static Analyzer getAnalyzer(){
return new StandardAnalyzer();
}
/**
* 得到索引磁盘存储器
* @param indexDir 存储位置
* @return
*/
public static Directory getDirectory(String indexDir){
Directory directory=null;
try {
directory= FSDirectory.open(Paths.get(indexDir));
}catch (Exception e){
e.printStackTrace();
}
return directory;
}
/**
* 获取读索引实体,并打印读到的索引信息
* @return
*/
public static IndexReader getIndexReader(){
IndexReader reader=null;
try {
reader= DirectoryReader.open(getDirectory(indexDir));
//通过reader可以有效的获取到文档的数量
System.out.println("当前存储的文档数::"+reader.numDocs());
System.out.println("当前存储的文档数,包含回收站的文档::"+reader.maxDoc());
System.out.println("回收站的文档数:"+reader.numDeletedDocs());
} catch (Exception e) {
e.printStackTrace();
}
return reader;
}
/**
* 写索引测试,借助Luke观察结果
* @throws Exception
*/
@Test
public void Testinsert() throws Exception{
IndexWriter writer=getIndexWriter(indexDir);
writer.close();
getIndexReader();
}
/**
* 删除索引测试,借助Luke观察结果
* @throws Exception
*/
@Test
public void TestDelete()throws Exception{
//测试删除前我们先把上次的索引文件删掉,或者换个目录
IndexWriter writer=getIndexWriter(indexDir);
QueryParser parser=new QueryParser("ids", getAnalyzer());//指定Document的某个属性
Query query=parser.parse("2");//指定索引内容,对应某个分词
Term term=new Term("names","kl");
//参数是一个选项,可以是一个query,也可以是一个term,term是一个精确查找的值
writer.deleteDocuments(query);//此时删除的文档并不会被完全删除,而是存储在一个回收站中的,可以恢复
writer.forceMergeDeletes();//强制合并删除的索引信息,索引量大的时候不推荐使用,真正的删除
// writer.commit(); //更改索引要提交,和提交数据库事务一个概念,真正的删除
writer.close();
getIndexReader();
}
/**
* 更新操作测试,借助Luke观察结果
* @throws Exception
*/
@Test
public void TestUpdate()throws Exception{
// Lucene并没有提供更新,这里的更新操作相当于新增,他并不会去掉原来的信息
IndexWriter writer = getIndexWriter(indexDir);
try {
Document doc = new Document();
doc.add(new StringField("id","1",Field.Store.YES));
doc.add(new StringField("names","ckl",Field.Store.YES));
doc.add(new StringField("describes","chenkailing",Field.Store.NO));
writer.updateDocument(new Term("id","1"), doc);
} catch (Exception e) {
e.printStackTrace();
} finally {
if(writer!=null) writer.close();
}
}
/**
* 查询测试
*/
@Test
public void TestSearchaer(){
try {
IndexReader reader = getIndexReader();
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser=new QueryParser("names", getAnalyzer());//指定Document的某个属性
Query query=parser.parse("kl");//指定索引内容,对应某个分词
Term term=new Term("names","kl");
//参数是一个选项,可以是一个query,也可以是一个term,term是一个精确查找的值
TopDocs hits = searcher.search(query, 10);
for(ScoreDoc sd:hits.scoreDocs) {
Document doc = searcher.doc(sd.doc);
System.out.println(
doc.get("names")+"["+doc.get("describes")+"]-->"+doc.get("ids"));
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
