前言
就拿百度说事吧,使用百度搜索引擎的时候,你会发现,卧槽,这什么玩意,前面的几个结果根本就不是老子要的东西,都是些推广的内容,而结果匹配度高的还排在老后面去了,百度这铲屎的干嘛吃的!这也不能怪百度,毕竟人家靠推广吃饭的,自然把交了钱的结果权值提高了 !这算文档域加权的使用场景吧
说明
所谓索引域加"权",就是根据需求的不同,对不同的关键值或者不同的关键索引分配不同的权值,因为查询的时候Lucene的评分机制和权值的高低是成正比的,这样权值高的内容更容易被用户搜索出来,而且排在前面。在Lucene3.x版本的时候可以给文档加权,到4.x版本后就取消了给文档加权了,就只有给文档域加权了,如果想达到给文档加权的效果,就要该文档的每个域都加权处理
ps:博主前篇博文谈过IKAnalyzer与paoding中文分词,今天我们使用的是可用于中日韩的二元分词器CJKAnalyzer
闲话少说,直接上代码,看结果
package com.kl.luceneDemo;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Paths;
/**
* @author kl by 2016/3/19
* @boke www.kailing.pub
*/
public class FieldSetBoostTest {
//索引目录
String indexDir="E:\\LuceneIndex";
//测试数据
String theme="中国";
String []title={"中国是一个伟大的国家","我爱你的的祖国,美丽的中国","是什么,中国令美日等国虎视眈眈"};
/**
* Lucence5.5返回IndexWriter实例
* @param directory
* @return
*/
public IndexWriter getIndexWriter(Directory directory){
Analyzer analyzer=new CJKAnalyzer();//中日韩二元分词
IndexWriterConfig writerConfig=new IndexWriterConfig(analyzer);
IndexWriter writer=null;
try {
writer =new IndexWriter(directory,writerConfig);
}catch (Exception e){
e.printStackTrace();
}
return writer;
}
public Directory getDirctory(String indexDir){
Directory directory=null;
try {
directory=FSDirectory.open(Paths.get(indexDir));
}catch (IOException e){
e.printStackTrace();
}
return directory;
}
/**
* 创建索引不加权
* @throws Exception
*/
public void Indexer()throws Exception{
IndexWriter writer=getIndexWriter(getDirctory(indexDir));
Document doc=null;
for(String str:title){
doc=new Document();
//Lucence5.5 Fileld有多个实现,StringFIeld不分词 TextField分词
doc.add(new StringField("theme",theme, Field.Store.YES));
Field field=new TextField("title",str, Field.Store.YES);
doc.add(field);
writer.addDocument(doc);
}
writer.close();
}
/**
* 创建索引,指定文档域加权
* @throws Exception
*/
public void IndexerSetBoot()throws Exception{
IndexWriter writer=getIndexWriter(getDirctory(indexDir));
Document doc=null;
for(String str:title){
doc=new Document();
//Lucence5.5 Fileld有多个实现,StringFIeld不分词 TextField分词
doc.add(new StringField("theme",theme, Field.Store.YES));
Field field=new TextField("title",str, Field.Store.YES);
if(str.indexOf("是什么")!=-1)
field.setBoost(2);//提高权值
doc.add(field);
writer.addDocument(doc);
}
writer.close();
}
@Test
public void searcherTest()throws Exception{
IndexerSetBoot();
// Indexer();
IndexReader reader= DirectoryReader.open(getDirctory(indexDir));
IndexSearcher is=new IndexSearcher(reader);
System.out.println("总的文档数:"+reader.numDocs());
QueryParser qp=new QueryParser("title",new CJKAnalyzer());
Query query=qp.parse("中国");
TopDocs tDocs=is.search(query,11);//一次查询多少个结果
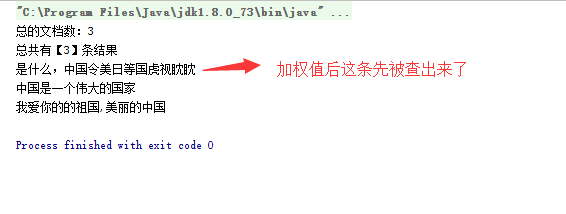
System.out.println("总共有【"+tDocs.totalHits+"】条结果");
for (ScoreDoc scoredoc:tDocs.scoreDocs){
Document doc = is.doc(scoredoc.doc);
System.out.println(doc.getField("title").stringValue());
}
}
}
加权和不加权的结果如下